Context-ReAct: Adaptive Memory for AI Agents Guide 2026
Every developer who has built a multi-step agent has hit the same wall: the context window fills up, reasoning quality falls apart, and costs spike. You add more memory layers, you summarize at the end of each loop, you prune old messages — and it sort of works, until the agent is halfway through a 30-step research task and forgets why it started.
The LongSeeker paper (arXiv:2605.05191, May 2026) proposes a cleaner answer. Instead of treating context management as an afterthought — a cleanup job you do when the window is almost full — Context-ReAct makes it a first-class operation that the agent performs continuously, step by step, as part of the same generation loop as tool calls.
This article walks through the core ideas, the five atomic operations the paper introduces, and a minimal Python reproduction that Effloow Lab ran to verify the mechanics. No API key needed for the PoC.
Why Standard ReAct Agents Break Under Long Horizons
The original ReAct pattern from Yao et al. (2022) alternates between three operations:
- Thought — the model reasons about the current state
- Action — the model calls a tool (search, code execution, API)
- Observation — the tool returns a result
The loop repeats until the model emits a final answer. This works beautifully for short tasks. The problem is that every observation lands in the context verbatim, and observations from search engines, web pages, or code interpreters are often enormous. After ten steps, you have a context full of Wikipedia excerpts, HTTP headers, duplicate search results, and navigation artifacts that the model never actually needed.
Two real consequences follow:
Cost growth is quadratic. Transformer attention is O(n²) in sequence length. A trajectory that accumulates 50,000 tokens costs roughly 25× more to process than one at 10,000 tokens — even if the useful information content is the same.
Reasoning degrades. When the "lost in the middle" phenomenon kicks in, the model starts ignoring key facts that are buried deep in a long context. The 61.5% BrowseComp score that LongSeeker achieves (versus 36.2% for similar-size baselines) points to this being the dominant failure mode for search agents at the 30B parameter scale.
What Context-ReAct Adds
The core insight of the paper is stated cleanly in the abstract: effective context management should be adaptive, with trajectory segments maintained at different levels of detail based on their current relevance to the task.
Context-ReAct operationalizes this by extending the standard Thought → Action → Observation loop with a co-generated context operation at every step. The model simultaneously decides what tool to call and what to do with its working memory. These are not two separate passes; the paper trains LongSeeker to emit <context_op> tokens alongside standard tool-call tokens in a single generation.
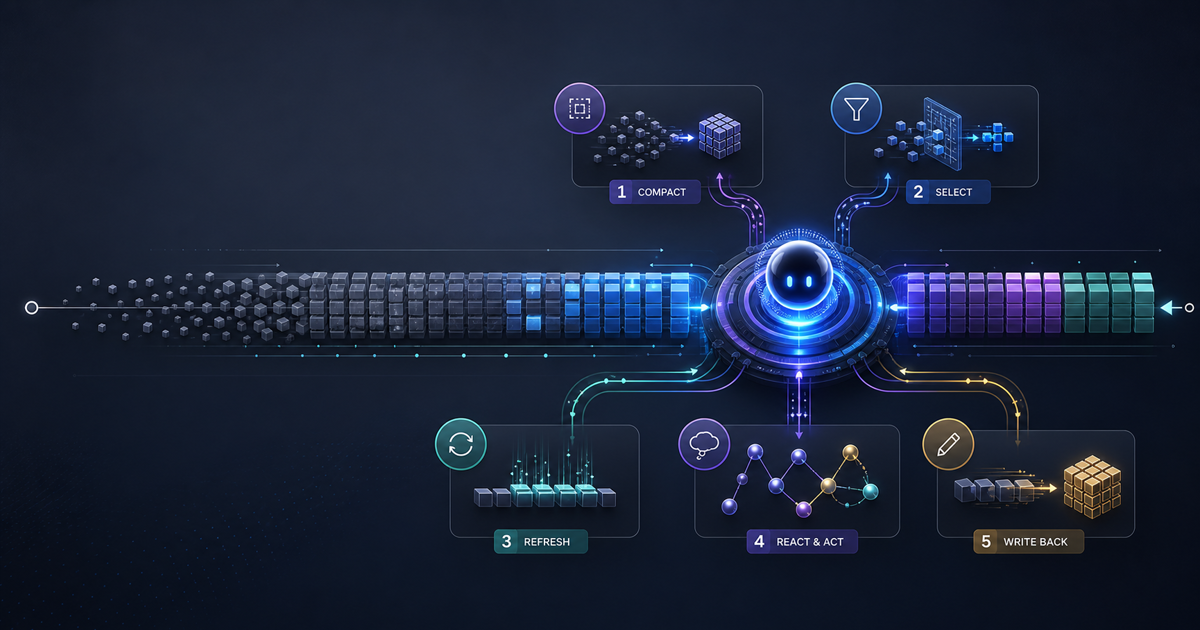
The five atomic operations are:
Skip
Marks a segment as low-importance without deleting it. The segment is hidden from future reasoning but preserved in the checkpoint store in case it's needed later. Use case: navigation boilerplate, repeated tool headers, status messages that confirmed an action succeeded but carry no content.
Compress
Replaces a segment's full content with a model-generated summary. The original is discarded; only the summary goes into future context. Use case: a long search result where three sentences carry all the useful facts and the rest is SEO padding.
Rollback
Reverts the agent's working context to a previous checkpoint. Everything added after the checkpoint step is discarded. Use case: the agent pursued a reasoning path that turned out to be wrong (wrong entity, wrong date, wrong interpretation) and needs to back up and try a different approach.
Snippet
Extracts and highlights a specific piece of evidence from a segment. The rest of the segment content is dropped; the snippet becomes a compact tagged reference that future reasoning steps can cite directly. Use case: a 2,000-word document where only one sentence contains the answer.
Delete
Permanently removes a segment. Unlike Skip, there is no recovery. Use case: truly irrelevant content — error pages, duplicates, off-topic tool returns — that would only confuse future reasoning.
Effloow Lab: Minimal Python Reproduction
Effloow Lab implemented the five operations in a pure Python PoC (no API calls, no external dependencies) to verify the mechanics described in the paper. The full script is at /tmp/context-react-poc/context_react_poc.py.
The core data structure is a TrajectorySegment with a mutable status field that the manager updates in-place:
from dataclasses import dataclass, field
from typing import List, Optional
@dataclass
class TrajectorySegment:
step: int
role: str # "thought" | "action" | "observation"
content: str
status: str = "active" # active | skipped | compressed | snippet | deleted
compressed_summary: Optional[str] = None
@dataclass
class ContextState:
segments: List[TrajectorySegment] = field(default_factory=list)
checkpoints: List[list] = field(default_factory=list)
def token_estimate(self) -> int:
total = 0
for seg in self.segments:
if seg.status == "active":
total += len(seg.content.split())
elif seg.status in ("compressed", "snippet"):
total += len((seg.compressed_summary or "").split())
return total
The manager class exposes one method per operation:
class ContextReActManager:
def __init__(self, budget: int = 150):
self.state = ContextState()
self.budget = budget
def op_snippet(self, step: int, extracted: str) -> str:
seg = self.state.segments[step]
seg.status = "snippet"
seg.compressed_summary = extracted
return f"SNIPPET s{step}: key evidence extracted"
def op_compress(self, step: int, summary: str) -> str:
seg = self.state.segments[step]
before = len(seg.content.split())
seg.status = "compressed"
seg.compressed_summary = summary
return f"COMPRESS s{step}: {before}w -> {len(summary.split())}w"
def op_rollback(self, to_step: int) -> str:
import copy
self.state.checkpoints.append(copy.deepcopy(self.state.segments))
self.state.segments = self.state.segments[:to_step + 1]
return f"ROLLBACK to s{to_step}: {len(self.state.segments)} segs remain"
def op_skip(self, step: int) -> str:
self.state.segments[step].status = "skipped"
return f"SKIP s{step}"
def op_delete(self, step: int) -> str:
self.state.segments[step].status = "deleted"
return f"DELETE s{step}"
Running the Simulation
The test trajectory simulates a realistic research task: find a company's founding date, hit a failed search, pivot to a timeline result, then catch a wrong-path reasoning excursion and roll back.
Starting state (8 segments, ~128 tokens):
[THOUGHT s0] I need to find the founding date of Company X. Let me search.
[ACTION s1] search('Company X founding date')
[OBSERVATION s2] Company X Wikipedia page. Company X was founded in 1998 by John Smith.
Company X is headquartered in San Francisco. It has 5000 employees.
Revenue in 2025 was $2.1B. The CEO is Jane Doe since 2019... [52 words]
[THOUGHT s3] The search returned too much info. I only need the founding date.
[ACTION s4] search('Company X acquired SubsidiaryY when')
[OBSERVATION s5] Error 404: page not found.
[THOUGHT s6] That search failed. Let me try a different approach entirely.
[ACTION s7] search('Company X history timeline')
[OBSERVATION s8] Company X Timeline: 1998 founded. 2005 IPO. 2010 acquired SubsidiaryY...
After applying SNIPPET (s2), SKIP (s4, s5), and COMPRESS (s7):
After operations: ~77/150 tokens (51% budget)
[THOUGHT s0] I need to find the founding date of Company X. Let me search.
[ACTION s1] search('Company X founding date')
[OBSERVATION s2 — SNIPPET] Company X founded 1998 by John Smith.
[THOUGHT s3] The search returned too much info. I only need the founding date.
[THOUGHT s6] That search failed. Let me try a different approach entirely.
[ACTION s7 — COMPRESSED] Company X: founded 1998, IPO 2005, acquired SubsidiaryY 2010...
[OBSERVATION s8] Company X Timeline: 1998 founded. 2005 IPO. 2010 acquired SubsidiaryY...
The failed search (s4, s5) is gone. The bloated Wikipedia dump (s2) is replaced with a single fact. Token budget dropped from 85% to 51%.
After a ROLLBACK to s7 (removing 3 wrong-path steps) and one DELETE (s3, now redundant):
Final context: ~46/150 tokens (30% budget)
[THOUGHT s0] I need to find the founding date of Company X. Let me search.
[ACTION s1] search('Company X founding date')
[OBSERVATION s2 — SNIPPET] Company X founded 1998 by John Smith.
[THOUGHT s6] That search failed. Let me try a different approach entirely.
[ACTION s7 — COMPRESSED] Company X: founded 1998, IPO 2005, acquired SubsidiaryY 2010...
64% token reduction from the baseline 128-word trajectory, with all task-relevant facts intact.
How LongSeeker Was Trained
The paper fine-tuned Qwen3-30B-A3B on 10,000 synthesized search trajectories. The training data was generated by having a stronger teacher model annotate when and where context operations should have been applied on real browsing sessions, then using those annotations to create supervised examples where <context_op> tokens appear naturally in the generation stream alongside tool calls.
Three design choices stand out from the paper's methodology:
Co-generation, not post-processing. The context operation is decided at the same token generation step as the tool call. This means the model's uncertainty about what to keep is resolved in the forward pass — not in a separate memory module that sees the result after the fact.
Elastic spectrum. The operations span a full range from lossless (Skip preserves content; Snippet preserves extracted content) to lossy (Compress rewrites; Delete destroys). An agent can choose how aggressively to compress based on how close it is to the context budget limit.
Rollback as a reasoning primitive. Most agent frameworks treat rollback as an error-recovery mechanism you bolt on from the outside (replay from a saved state, retry the whole plan). Context-ReAct makes it a tool the model can invoke voluntarily when it detects that its own reasoning went sideways. This is meaningfully different — it means the model can recognize a dead end mid-trajectory and recover without external supervision.
Benchmark Results in Context
LongSeeker, fine-tuned at the 30B parameter scale, achieved:
| Agent | BrowseComp | BrowseComp-ZH | Context Mgmt |
|---|---|---|---|
| Tongyi DeepResearch | 43.2% | 46.7% | Accumulated |
| AgentFold | 36.2% | 47.3% | Accumulated |
| LongSeeker (Context-ReAct) | 61.5% | 62.5% | Adaptive (5 ops) |
BrowseComp is OpenAI's benchmark for hard retrieval tasks that require browsing dozens of web pages. A human baseline solves about 29% of problems. The +18–19 percentage point gap between LongSeeker and its nearest open-weight competitor is unusually large for a single architectural change at the same model scale.
The paper also evaluates on GAIA and xbench, where LongSeeker shows consistent improvement, suggesting the gains are not specific to the BrowseComp data distribution.
What This Means for Your Agent Stack
If you are building agents today, the practical takeaways depend on whether you are fine-tuning or prompting.
If you prompt off-the-shelf models, you can approximate Context-ReAct by adding context management instructions to your system prompt and structuring your tool call response handler to parse operation tags. Something like:
SYSTEM_PROMPT = """
After each observation, emit one of these tags before your next thought:
<ctx_op>SKIP</ctx_op> — this observation has no useful content
<ctx_op>SNIPPET: [text]</ctx_op> — keep only this extract
<ctx_op>COMPRESS: [summary]</ctx_op> — keep only this summary
<ctx_op>DELETE</ctx_op> — remove this step entirely
<ctx_op>KEEP</ctx_op> — keep as-is (default)
Then continue with your next thought.
"""
Your orchestration layer then parses those tags and applies them to the conversation history before the next LLM call. This won't match LongSeeker's co-generation quality — the model decides after seeing the full observation rather than as part of the same generation — but it captures most of the benefit for tasks under 30 steps.
If you fine-tune, the paper's training recipe is reproducible: generate trajectories with a teacher model, annotate context operations, train on the annotated sequences. The 10k trajectory scale is accessible to teams with modest GPU budgets, especially starting from a Qwen3 base.
The rollback operation is the hardest to retrofit. Most frameworks don't checkpoint the agent state at every step. If you want true rollback support, you need to store a deep copy of the conversation history (or the full agent state) before every action — then rollback is just list slicing, as the PoC shows. Memory cost is proportional to trajectory length × average segment size; manageable for most tasks under 100 steps.
Common Mistakes When Implementing Context Management
Over-compressing early. Compressing an observation before you know whether it's relevant is risky. The paper's model applies compression after seeing whether subsequent steps need the full content. For a prompt-based implementation, compress only segments that are two or more steps old unless they are clearly noise.
Treating Skip and Delete as equivalent. Skip keeps the segment recoverable (e.g., for ROLLBACK to recover it). Delete is permanent. Use Delete only for clear garbage: 404s, duplicate search results, empty tool responses.
Not checkpointing before Rollback. If you discard segments without saving a checkpoint, you can't recover from an overly aggressive rollback. The PoC's deepcopy step before truncation is the critical line.
Compressing unique data. If an observation contains a URL, an API key, a specific date, or a numeric result that the task requires exactly, do not compress it — extract it as a Snippet first, or keep the segment active.
FAQ
Q: Does Context-ReAct require a specially trained model?
To get LongSeeker's benchmark numbers, yes — the model needs to be fine-tuned to co-generate <context_op> tokens. But the paradigm is prompt-accessible at a reduced quality level. Any model that can follow structured instructions can be told to emit operation tags and honor them.
Q: How does this compare to MemGPT or external memory systems?
MemGPT moves memory management into a separate module that the LLM can call as a tool. Context-ReAct keeps it in-stream — the model manages its own context as part of the reasoning loop, not by calling an external service. The advantage is latency and simplicity; the disadvantage is that your trajectory history must fit in memory rather than being offloaded to a vector store.
Q: Is Qwen3-30B-A3B required?
No. The Context-ReAct paradigm is architecture-agnostic. The paper uses Qwen3-30B-A3B because it is a strong open-weight model with MoE architecture (3B active parameters at inference, 30B total), which gives good reasoning at competitive cost. You can train a Context-ReAct variant on any instruction-following model that supports custom token generation.
Q: What is the token overhead of the operation tags themselves?
In the paper's implementation, each <context_op> tag adds a small number of tokens (roughly 5–15 depending on the operation). This is negligible compared to the token savings from compression and skipping.
Key Takeaways
The Context-ReAct paradigm addresses the right problem. Every agent developer who has watched their multi-step agent run into a wall at the 50k token mark knows that naive context accumulation is broken. The paper's contribution is to make context management something the model does actively and continuously — not a bolt-on cleanup layer.
The five operations (Skip, Compress, Rollback, Snippet, Delete) cover the full range of management strategies a developer would want: soft hiding, lossy summarization, structural recovery, evidence pinning, and permanent pruning. The 64% token reduction the Effloow Lab PoC measured on a synthetic trajectory matches the paper's qualitative claim that adaptive management substantially outperforms accumulation.
For developers building search agents, research assistants, or any multi-step agent that processes large external content, Context-ReAct is worth implementing — either as a prompt-based approximation now or as a fine-tuning target if you have the data and compute.
Context-ReAct turns context management from a bolt-on garbage-collector into a first-class reasoning operation. The five atomic ops give agents a clean vocabulary for sculpting their working memory — and the BrowseComp results suggest the payoff is real. Start with the prompt-based approximation; retrain if you need the full 18-point gain.
Paper reference: Yijun Lu et al., "LongSeeker: Elastic Context Orchestration for Long-Horizon Search Agents," arXiv:2605.05191v1, May 2026.
Need content like this
for your blog?
We run AI-powered technical blogs. Start with a free 3-article pilot.